Popular Comments
Recent Discussion
I can see some arguments in your direction but would tentatively guess the opposite.
In the late 19th century, two researchers meet to discuss their differing views on the existential risk posed by future Uncontrollable Super-Powerful Explosives.
- Catastrophist: I predict that one day, not too far in the future, we will find a way to unlock a qualitatively new kind of explosive power. This explosive will represent a fundamental break with what has come before. It will be so much more powerful than any other explosive that whoever gets to this technology first might be in a position to gain a DSA over any opposition. Also, the governance and military strategies that we were using to prevent wars or win them will be fundamentally unable to control this new technology, so we'll have to reinvent everything on the fly or die in
Maybe we have different definitions of DSA: I was thinking of it in terms of 'resistance is futile' and you can dictate whatever terms you want because you have overwhelming advantage, not that you could eventually after a struggle win a difficult war by forcing your opponent to surrender and accept unfavorable terms.
If say the US of 1965 was dumped into post WW2 Earth it would have the ability to dictate whatever terms it wanted because it would be able to launch hundreds of ICBMS at enemy cities at will. If the real US of 1949 had started a war against t...
This posts assumes basic familiarity with Sparse Autoencoders. For those unfamiliar with this technique, we highly recommend the introductory sections of these papers.
TL;DR
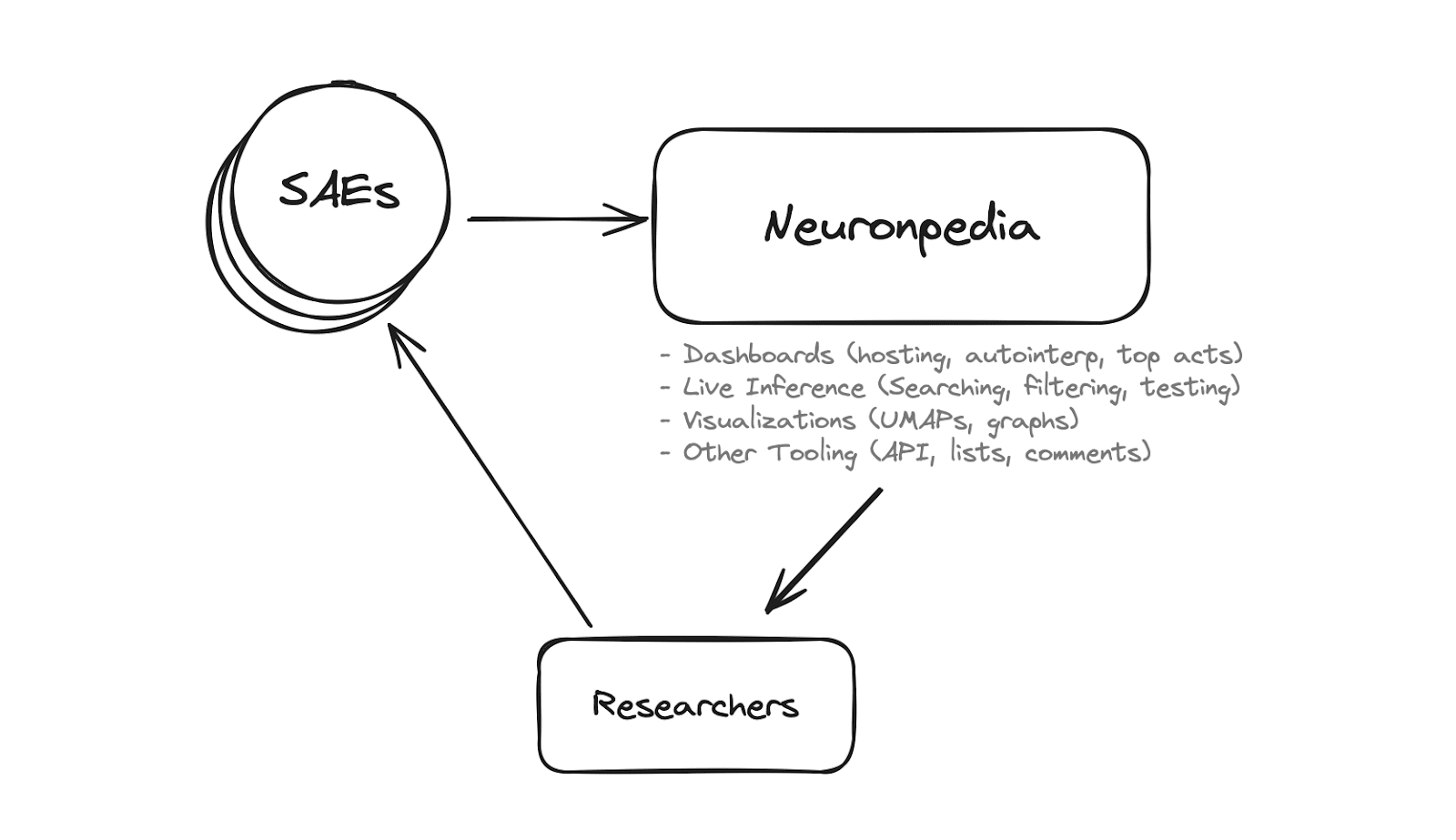
Neuronpedia is a platform for mechanistic interpretability research. It was previously focused on crowdsourcing explanations of neurons, but we’ve pivoted to accelerating researchers for Sparse Autoencoders (SAEs) by hosting models, feature dashboards, data visualizations, tooling, and more.
Important Links
- Explore: The SAE research focused Neuronpedia. Current SAEs for GPT2-Small:
- Upload: Get your SAEs hosted by Neuronpedia: fill out this <5 minute application
- Participate: Join #neuronpedia on the Open Source Mech Interp Slack
Neuronpedia has received 1 year of funding from LTFF. Johnny Lin is full-time on engineering, design, and product, while Joseph Bloom is supporting with...
I'm interested in using the SAEs and auto-interp GPT-3.5-Turbo feature explanations for RES-JB for some experiments. Is there a way to download this data?
A couple years ago, I had a great conversation at a research retreat about the cool things we could do if only we had safe, reliable amnestic drugs - i.e. drugs which would allow us to act more-or-less normally for some time, but not remember it at all later on. And then nothing came of that conversation, because as far as any of us knew such drugs were science fiction.
… so yesterday when I read Eric Neyman’s fun post My hour of memoryless lucidity, I was pretty surprised to learn that what sounded like a pretty ideal amnestic drug was used in routine surgery. A little googling suggested that the drug was probably a benzodiazepine (think valium). Which means it’s not only a great amnestic, it’s also apparently one...
Yeah, seems like a kinda bad feedback loop. It doesn't seem to usually happen in that the comments I've seen upvoted in that section usually don't get this extremely many upvotes on a comment this short.
I don't have a great solution. We could do something that's more clever and algorithmic, which doesn't seem crazy but I am also hesitant to do because it's a lot of work and also I like more straightforward and simple algorithms for transparency reasons.
Introduction
A recent popular tweet did a "math magic trick", and I want to explain why it works and use that as an excuse to talk about cool math (functional analysis). The tweet in question:

This is a cute magic trick, and like any good trick they nonchalantly gloss over the most important step. Did you spot it? Did you notice your confusion?
Here's the key question: Why did they switch from a differential equation to an integral equation? If you can use when , why not use it when ?
Well, lets try it, writing for the derivative:
So now you may be disappointed, but relieved: yes, this version fails, but at least it fails-safe, giving you the trivial solution, right?
But no, actually can fail catastrophically, which we can see if we try a nonhomogeneous equation...
Oh, very cool, thanks! Spoiler tag in markdown is:
:::spoiler
text here
:::
I think you should write it. It sounds funny and a bunch of people have been calling out what they see as bad arguements that alginment is hard lately e.g. TurnTrout, QuintinPope, ZackMDavis, and karma wise they did fairly well.
I didn’t use to be, but now I’m part of the 2% of U.S. households without a television. With its near ubiquity, why reject this technology?
The Beginning of my Disillusionment
Neil Postman’s book Amusing Ourselves to Death radically changed my perspective on television and its place in our culture. Here’s one illuminating passage:
...We are no longer fascinated or perplexed by [TV’s] machinery. We do not tell stories of its wonders. We do not confine our TV sets to special rooms. We do not doubt the reality of what we see on TV [and] are largely unaware of the special angle of vision it affords. Even the question of how television affects us has receded into the background. The question itself may strike some of us as strange, as if one were
To make an analogy to diet, you essentially replaced a sugar fix from eating Snickers bars with eating strawberries. Gradation matters!
I had a similar slide with my technologies, as I explained in the post. I eventually landed on reading books. But even that became a form of intellectual procrastination as I wrote in my latest LW post.
Pretending not to see when a rule you've set is being violated can be optimal policy in parenting sometimes (and I bet it generalizes).
Example: suppose you have a toddler and a "rule" that food only stays in the kitchen. The motivation is that each time food is brough into the living room there is a small chance of an accident resulting in a permanent stain. There's cost to enforcing the rule as the toddler will put up a fight. Suppose that one night you feel really tired and the cost feels particularly high. If you enforce the rule, it will be much more p...
If you’ve ever been to Amsterdam, you’ve probably visited, or at least heard about the famous cookie store that sells only one cookie. I mean, not a piece, but a single flavor.
I’m talking about Van Stapele Koekmakerij of course—where you can get one of the world's most delicious chocolate chip cookies. If not arriving at opening hour, it’s likely to find a long queue extending from the store’s doorstep through the street it resides. When I visited the city a few years ago, I watched the sensation myself: a nervous crowd awaited as the rumor of ‘out of stock’ cookies spreaded across the line.

The store, despite becoming a landmark for tourists, stands for an idea that seems to...
